

Au commencement…
Chez Toucan Toco, chaque client dispose de son instance dédiée, et donc de sa propre stack: MongoDB dédié, Redis dédié, pools de process gunicorn / celery dédiés. À chaque nouveau projet ou pilote, on est amené à déployer une nouvelle instance.
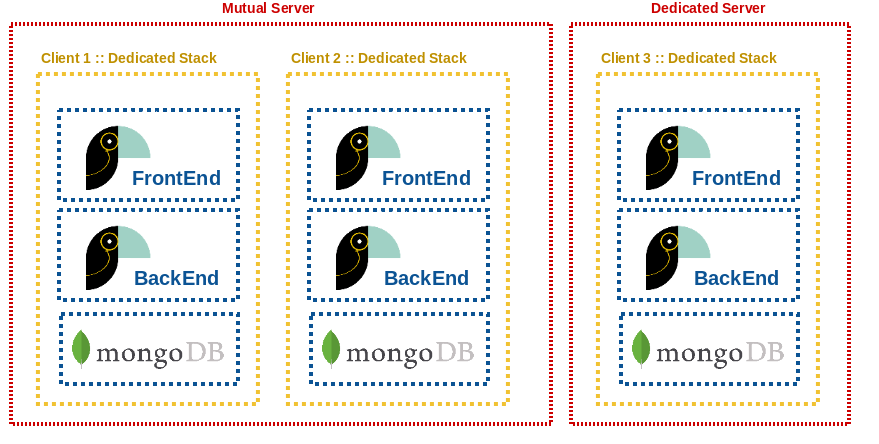
Très vite pour déployer une nouvelle stack, nous avons fait une suite de playbooks Ansible. Ceux-ci sont en charge de provisionner la machine cible avec la stack et toutes ses dépendances, d’ajuster l’environnement (comme les règles fail2ban, etc…), mais rien n’était géré pour notre supervision.
Plutôt que de gérer le monitoring des différentes briques de chaque instance avec un outil agent-based comme Nagios (à déployer, configurer et mettre à jour sur chaque serveur), la première version de notre monitoring était réalisée à l’aide du free trial proposé par StatusCake. Ce service permet de pinger à intervalle régulier une URL donnée, et de remonter des alertes via Slack ou mail.
Le problème : tout faire manuellement
Comme cette partie n’était pas automatisée, la création des tests StatusCake était faite manuellement en allant sur l’interface web comme le décrivait notre documentation pour l’initialisation d’une nouvelle stack. La création de checks sur l’interface de StatusCake est relativement simple mais reste fastidieuse avec la multiplication des projets. A chaque fois il faut se connecter à l’interface, retrouver les credentials, être certain qu’on crée le test avec les bonnes options comme les autres tests, cliquer, cliquer et encore cliquer… Du coup personne ne veut le faire et on s’expose à des erreurs.

La peine est la même lorsqu’on doit mettre à jour les tests (par exemple pour ajouter des conditions ou des paramètres). On comprend vite que le passage à l’échelle va vite être compromis.
La solution avec Ansible !
Avec la multiplication des clients et des projets, le besoin d’automatiser la création et la mise à jour du monitoring s’est donc rapidement fait sentir. Sachant que le deploiement et la mise à jour de nos stacks sont déjà automatisés par nos scripts Ansible… Pourquoi ne pas y déléguer la création de ces checks directement ?
Dans notre cas, on souhaite disposer de différents types de checks concernant la santé de nos services :
- un check pour s’assurer que notre service est bien up
- un check pour s’assurer que ce service arrive à communiquer avec les différentes briques dont il dépend (MongoDB, Redis, etc.)
Ces deux points correspondent à la distinction entre liveness et readiness, bien décrite dans un article d’Octo: Liveness et readiness probes: Mettez de l’intelligence dans vos clusters:
- liveness : si le check n’a pas de réponse alors on lève une alerte, le service est considéré comme KO
- readiness : suivant la réponse du check, on sait si notre service est “prêt à être utilisé” : ce n’est pas parce qu’on a une réponse que le service est OK
L’implémentation de ces checks passe par la mise à disposition de 2 routes dédiées, sur notre service :
@app.route('/liveness')
def liveness():
return "OK", 200
@app.route('/readiness')
def readiness():
try:
g.redis_connection.ping()
g.mongo_connection.server_info()
except (pymongo.errors.ConnectionFailure, redis.ConnectionError):
return "KO", 500
return "OK", 200
- liveness : si le check sur
/livenessne répond pas alors notre service est considéré KO quoi qu’il arrive - readiness : si le check sur
/readinessretourne 200 alors la stack est considérée comme OK car la connexion aux services tiers Redis et Mongo sont OK
Côté scripts Ansible, nous avons créé un module custom en python ansible-statuscake (forké à partir de p404/ansible-statuscake qui n’est aujourd’hui plus maintenu). Ce module s’utilise de cette façon:
- name: Create StatusCake test
local_action:
module: status_cake_test
username: "my-user"
api_key: "my-api-key"
name: "My service check"
url: "https://myservice.example.com"
state: "present"
test_type: "HTTP"
check_rate: 60 # on check toutes les minutes
Afin qu’Ansible puisse trouver ce module custom, il faut placer le script python status_cake_test.py dans le dossier library à la racine du playbook.
Note technique : ici, puisqu’on utilise une local_action, l’exécution a lieu sur la machine qui lance le déploiement, pas sur la machine cible. Dans un tel contexte, on peut donc bénéficier de l’interpréteur python et des packages pip de notre choix, sans dépendre de la machine cible. Cela nous a été utile pour réaliser un autre module ansible en python 3 / asyncio, qui nous a permis de réécrire certaines tâches en utilisant un modèle concurrent et ainsi nous faire gagner en vélocité de déploiement.
Quelques stats pour finir…
Aujourd’hui grâce à cette approche :
- nous avons créé et nous maintenons automatiquement environ 1000 tests pour nos 200 stacks
- la configuration des tests se fait via des variables Ansible qui sont committées, reviewées et appliquées automatiquement à chaque deploiement de stack
- lorsqu’on décomissione un projet, tous les tests associés sont automatiquement suppprimés : ainsi notre monitoring est toujours à l’image de notre production
- StatusCake nous permet de lever des alertes sur des codes HTTP, des patterns trouvés dans la réponse, des temps de réponse… et nous permet de faire plusieurs types de checks différents (de performance, des healthchecks,…)
- permet le calcul des SLA à l’échelle de chaque instance par une source externe qui est dans les mêmes conditions que nos clients, on a finalement qu’à extraire les données récoltés lors des tests