The goal of this article is to talk about a cache solution we use at Toucan Toco for the extraction phase of our ETL. It’s based on Pandas and on a particular file format : HDF5.
We want to reduce the extraction time of the ETL. Once tabular data are extracted then transformed from files, data sets and so on: they are loaded in a MongoDB base. The idea of this article is to show an easy solution based on Pandas and the file format HF5 to place the cache system. Having a cache to reduce extraction time isn’t always compulsory but it’s strongly advised.
We’d like to have a cache in a limited number of tables, with a way to make small and simple searches on the cache’s data. We want to share the cache on different devices : for a team, you only need to make the extraction once for all.
We are talking about a solution based on Pandas HDF5 file format. Here is a small introduction about HDF.
Small introduction to HDF and HDF5
HDF, stands for Hierarchical Data Format. It is a file format originally developed by the National Center for Supercomputing Application, an American organization, and is now maintained by the HDF Group. The last specification is HDF5, we will not talk about HDF4 in this article.
The need beyond HDF is the possibility to effectively and quickly read and write data sets, that are huge and different among themselves. These are mainly used for scientists, handling important amount of data on a regular basis.
A HDF5 file has a tree structure looking like a POSIX file system : a root and knots (group), and sheets (data sets). A data sets (file) may be directly put under the root, or filed into a group (directory). The information about the structure of the data sets are saved, and the data that it contains may be registered contiguously by default or separated in different blocs according to performance. Note that data can also be compressed.
There are two Python libraries that allow HDF5 files handling : h5py and PyTables. Pandas uses PyTables and allows us to save DataFrames in HDF5 files. This is the solution we chose to put data in cache after the extraction phase.
Cache with Pandas
Pandas has a function called pandas.HDFStore() that takes a text string as input like a path to a file and sends back a HDFStore. The HDFStore allows to read and write DataFrames in a HDF5 file. The insertion and suppression of a DataFrame is simple :
import pandas as pd
store = pd.HDFStore('chemin_vers_un_fichier.h5')
df = pd.read_csv('chemin_vers_un.csv')
store['pandas_rocks'] = df # Comme un dict Python !
df = pd.read_csv('chemin_vers_un_autre.csv')
store['pandas_rocks_so_hard'] = df
del store['pandas_rocks_so_hard'] # Oui, encore comme un dict Python From then on, we can place a simple and elegant cache system thanks to Pandas, pytables and HDF5.
The working process of this first cache is: to search if the id exists within the cache ; if yes, send it back, otherwise launch the extraction and put the DataFrame inside the cache.
Small traps
Everything is ok as long as the extraction of a data source doesn’t return a dict of DataFrames, instead of only one DataFrame.
The problem can appear when we directly connect the output of a Pandas function with the cache system: Pandas doesn’t always return a DataFrame, it can also return a dict of DataFrame. For example, this happens when the input sheet name of an excel file is None. The pandas.read_excel() function will then return a dict of DataFrame where each key is a sheet name.
Looking for troubles? This one inevitably comes with any cache system: how to invalidate a data? And how to be sure that a registered data matches the most recent version?
Invalidation of a cache entranc
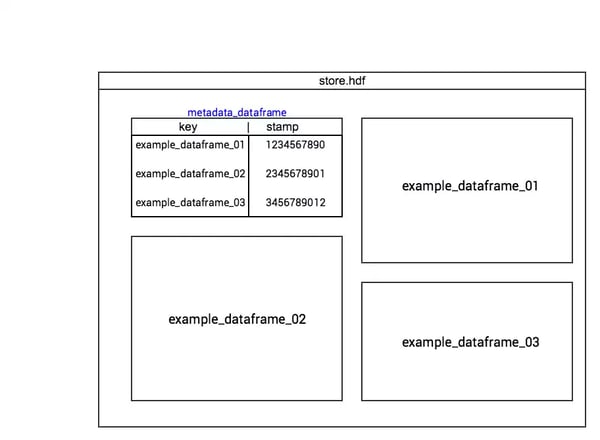
Considering that DataFrames are easy to handle, why not create a DataFrame of metadata, as a superblock in a file system?
In this case, we have a DataFrame to register relevant information on DataFrames in cache as a “stamp” that will allow us to invalidate or not a cached DataFrame.
To extract a data, we start by looking inside the DataFrame’s metadata. If the data is in cache, there is an entrance in the metadata cache with a key or associated path to it. If it’s not in the cache, it’s extracted and the produced DataFrame is put in cache. Don’t forget to add a line in the DataFrame’s metadata.
Concerning the validity of a data in cache, we can add a relatively simple system of “flag” depending on the type of datasource : local or external.
Local Data: files accessible through the file system of the device.
To use the last date modification of a file allows to know if the hidden data is valid or not.
External Data: API, database, files inaccessible via the file system.
It is more complicated to find a generic way to know when to invalidate a cache entry. We will not talk about a specific solution.
An example of external data source is the SQL database. If we have access to a request as a string, we can make a hash of it. Yes, SQL requests are hard coded, there can be good reasons for that ;)
From the hash and on, it’s a win: we only have to recalculate and compare it to the one which was registered. If they are different, it’s possible that the data which are going to be sent back won’t be the same. This is a pessimistic and very simple approach, but it works. Then, just ensure that the content of the database didn’t change.
Of course if we are using a lot of this or this database, we can find a way to create a “flag”. All you need is a bit of imagination… and a way to get the information, which isn’t always easy.
Furthermore, it’s very useful to have a simple way to manually invalidate a cache entry. For instance, if we are sure that the data in a database have been updated but the request isn’t.
Quick reminder: this cache is useful within the ETL. Once the data is extracted and transformed, they are obviously loaded in a base that will be used by the application.
Conclusion
To sum up, we can use Pandas and the HDF5 format not only to extract data from various sources, but to work on it and put a relatively simple but efficient system cache into position.
For instance, we have launched an extraction without cache on a project in order to compare. One hour without cache switched to few minutes with it. Let’s say that it allows you to save time and even money when you are using services such as Google Big Query.